The challenge of manipulating complex materials involves the identification of measurable quantities that offer insights into the system, which can then be utilized to make informed decisions and take appropriate actions. This essentially involves combining a perception system with a decision-making process. Markov decision processes (MDP) are well-suited to address the task of defining optimal strategies for material manipulation and particularly, Reinforcement Learning (RL) results suitable for this purpose due to its probabilistic nature accommodating the inherent uncertainty associated with characterizing the state of complex materials.
In MERGING we address the robotic, manipulation of complex objects and materials as the case of fabric manipulation to reduce wrinkles. The first step for the robotic manipulation of a fabric is the definition of the information required to perform the optimal actions for the manipulation of the material. For that purpose, the state of the system needs to be characterized, a prediction needs to be done to infer what is the next state of the system under the application of a given action, and a criterium to decide what action to take for a given target needs to be chosen.
What quantitative variables can be used in order to identify the state of a complex material and how to decide what to do in order to achieve a desired state?
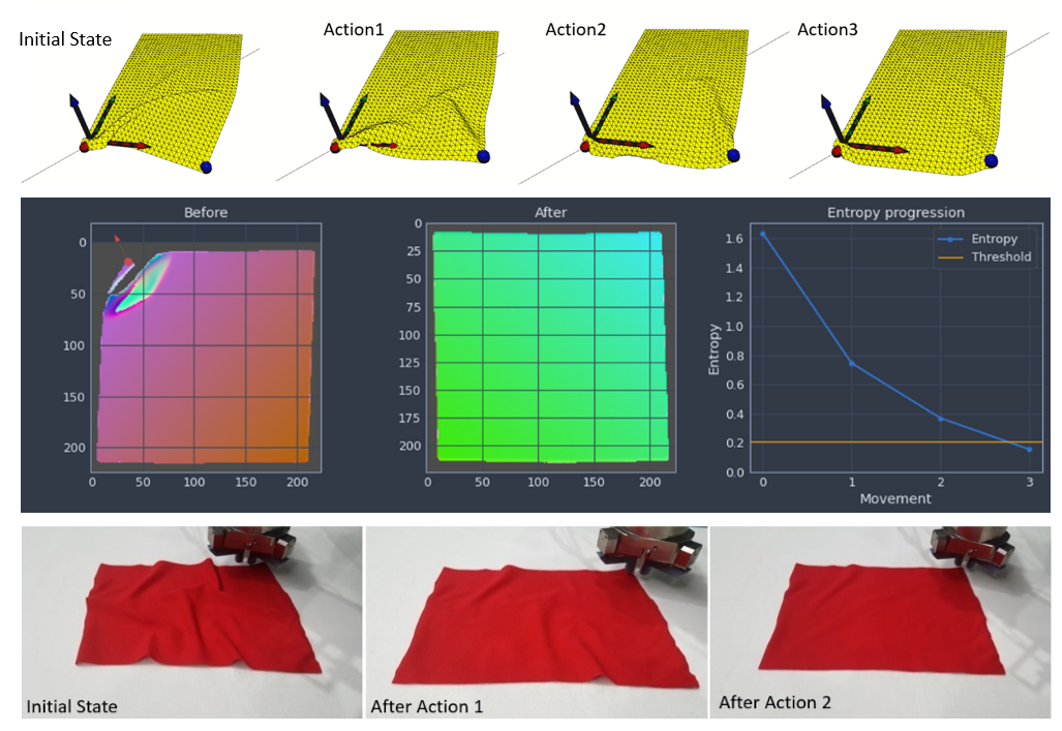
Entropy is usually thought as a measurement of how much information a message or distribution holds. In other words, how predictable such distribution is. A fabric can present different surface related features (patterns, textures…) that do not hold information about the amount of wrinkles it has. Consider this fact, the definition of the state of a fabric has been addressed based on data experimentally acquired through pointclouds. In the context of MERGING, entropy gives an idea about the distribution of the orientations of the normal vectors of a given area of points related with the fabric observed. Based on this quantity, the state of the fabric can be defined, a target for this quantity can be stablished, and the actions needed to achieve such target can be addressed.
In MERGING a Reinforcement Learning framework has been defined in order to let an AI system explore about what are the consequences of fabric manipulations in terms of wrinkledness dynamics. Based on such observations, the system can infer what is the optimal action to apply on each situation to reduce wrinkles in a fabric based on real observations.
In order to address the massive complex manipulation of fabrics to reduce wrinkles over the surface a specific digital environment has been developed as it is the clothsim environment made available as open access as part of the results of the MERGING Project. The detailed description of the simulation can be found on its own repository.The clothsim environment has been used for the cloth initial random configuration and later the training of the system. The learning routine has suggested different actions considering the Q-values (Q-matrix in a Q-Learning context) by an argmax function. After the application of the actions clothsim returned the transition of the fabric and the values of the Q-matrix have been updated following a Q-learning update rule where a reward function stablishes how good or bad the action was attending to the calculated entropy for each state. The Q-values are updated including a reward function which becomes positive is the entropy is decreased and remains negative in other case.
In the real scenario, after one observation of the pointcloud of a fabric, in order to select the actions to apply, the knowledge of the system encoded in the classic Q-matrix which is inferred by the system for a given state can be exploited. Such codification is done using a matrix that consider corners to manipulate and directions that can be taken within the fabric manipulation. The final outcome of the procedure is a set of three points: one static point to fix the fabric, a second point that represents the corner to be manipulated and a third point which represents the point where this last corner has to be placed (grab point, pull point initial coordinates, pull point final coordinates). The strategies have been also tested in a real scenario at AIMEN laboratory environment exploiting the knowledge gathered through training, the information captured through a point cloud and following the outcomes suggested by the analysis of the Q-matrix associated with the given state.
Our results show how entropy can be exploited as a metric to quantify the state of a complex material in order to manipulate it and drive a desired configuration. A training environment has been also presented as a requirement in order to deliver large amount of synthetic data that a Reinforcement Learning agent can acquire and later exploit in the real scenario.
Santiago Muiños Landin
Santiago Muiños Landin is the team leader in Artificial Intelligence and Data Analytics group at AIMEN. He has been involved in the definition of the Reinforcement Learning approach and contributed as the writer of this blog post.
Daniel Gordo Martín
Daniel Gordo Martín is an Industrial Engineer in Artificial Intelligence and Data Analytics at AIMEN. He has been an active contributing member of the MERGING project in validation and verification of the Artificial Intelligence approach and contributed as the writer of this blog post.
Acknowledgement: We would like to acknowledge the contribution of Carlos González Val, José Angel Segura Muros, David Castro Boga and Alberto Botana López for the Reinforcement Learning framework development, verification, and validation.